如何从零开始学习使用yolo
简述
本文档主要记录了如何从零开始学习使用yolo,包括环境搭建、模型训练和推理等内容。
yolo主要用于目标检测任务,旋转目标检测,姿态估计,实例分割,图像分类等任务。要做这些任务,就得有对应的模型,而训练模型需要有数据集,数据集的准备和标注是一个比较繁琐的过程,本文档也会介绍一些常用的数据集和标注工具。
环境
操作系统 笔者使用的是Ubuntu 24.04.3,windows环境下差别不大,按照本文步骤下载对应的安装包或资料即可,需要特殊处理的地方会在文中注明。
显卡 笔者显卡为GeForce RTX 4060。本文只涉及nvidia显卡如果是A卡请移步相关文档或使用下述提到的CPU训练。ubuntu下可使用nvdia-smi命令查看显卡型号和驱动版本,windows下可以在设备管理器中查看显卡型号,建议使用至少6GB显存的显卡,yolo模型训练需要较大的显存,建议至少4GB以上。不过也有纯CPU训练的版本,两者仅速度差距较大,CPU训练可能需要几倍甚至几十倍的时间。
内存 笔者的是32G内存,yolo模型训练需要较大的内存,建议至少16G以上。
如果上述环境条件均不满足或有较大差距,可以尝试使用云服务进行训练或抓紧买个新电脑吧。
相关概念介绍
YOLO版本选择
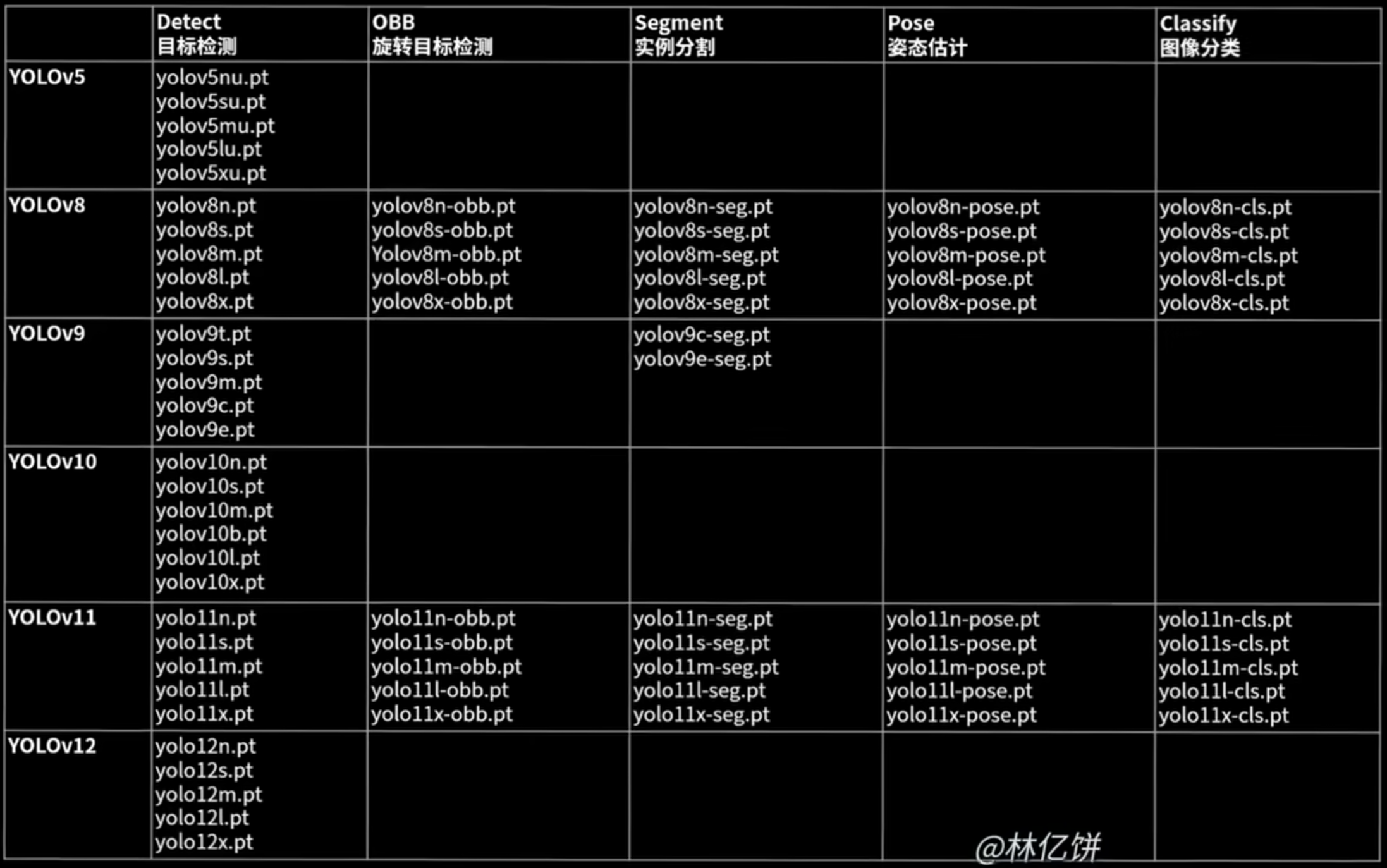
图片来源于BilbilUp主@林亿饼
YOLO截止目前已经出到YOLOv12(2026.2.13),其中YOLO8和YOLO11是比较常用的版本。从图中可以明显看出,YOLO主打目标检测,然后YOLOv11和YOLOv8可以完成所有任务,故建议初学者直接学习YOLOv8或YOLOv11,后续如果需要使用其他版本。本文将以YOLOv11为例进行讲解。
训练和推理
训练和推理是两个不同的概念,训练是指使用数据集对模型进行训练,使模型能够学习到数据中的特征和规律,最终得到一个能够对新数据进行预测的模型。而推理是指使用训练好的模型对新数据进行预测,比如输入一张图片,模型会输出图片中目标的位置和类别等信息。说人话就是训练是得到模型,推理是使用模型。
数据集
你只要知道自己要预测的目标,然后找到对应的数据集就行了,常用的数据集有COCO、VOC、ImageNet等,这些数据集都包含了大量的图片和对应的标注信息,可以用于训练和评估模型。但是,如果没有人做过你要的数据集,你也可以自己收集数据并进行标注,供模型使用。
环境配置
安装python环境
ubuntu自带python环境,windows需要自行安装python,浏览器直接搜索下载即可,建议使用python3.8以上版本,安装完成后可以使用python --version命令查看python版本。
安装anconda
anconda简介
anconda是一个非常好用的python环境管理工具,可以帮助我们创建和管理不同的python环境。初学者可能不知道什么是python环境,简单来说就是一个独立的空间,可以安装不同版本的python和不同的库,互不干扰。比如我有两个项目,一个需要python3.8,另一个需要python3.10,且两者需要的包版本不同,如果不使用环境管理工具,就会很麻烦,使用anconda就可以轻松解决这个问题。
anconda安装
下载方法可以直接进入anconda官网,选择对应的操作系统版本下载即可,但是要求登陆,其实不麻烦,因为可以跳过(doge)。或者国内最好从清华源进行下载。下载完成后按照提示安装即可,安装过程中可以选择添加anconda到环境变量,这样就可以在命令行中直接使用conda命令了。使用conda --version命令就可以查看conda版本,有输出则说明安装成功。
anconda使用
下面是一些基础的anconda命令:
conda create -n myenv python=3.11创建一个名为myenv的python3.11环境conda activate myenv激活myenv环境conda deactivate退出当前环境conda env list查看所有环境conda remove -n yoloenv --all删除yoloenv环境conda install package_name安装包,比如conda install numpy安装numpy包,此时使用pip安装也可以,pip install package_name,不过建议使用conda安装包,因为conda会自动解决依赖问题,而pip可能会出现依赖冲突的问题。
创建yolo环境
对于此次yolo项目,我们运行如下命令创建一个yolo环境:
1 | conda create -n yoloenv python=3.11 |
此时前面的(base)变为(yoloenv),说明已经成功激活了yoloenv环境。
注意,本文后续安装包的命令都是在yoloenv环境下执行的,如果没有激活环境,可能会出现找不到命令或包的错误。
安装pytorch
先根据电脑显卡硬件选择正确的pytorch版本,可对照下表查询自己需要的版本:
| 显卡 | PyTorch版本 | 备注 |
|---|---|---|
| 50系英伟达 | 最新+CUDA12.8 | 只能装这个 |
| 非50系英伟达 | 2.5.0+CUDA11.8 | CUDA版本低于电脑驱动CUDA版本都能用 |
| 不带NVIDIA显卡 | 2.5.0+CPU | 当初买错电脑了 |
下面将以NVIDIA非50系显卡为例,安装pytorch2.5.0+CUDA11.8版本,其他版本的安装方法类似,直接替换版本号即可:
检查驱动
首先在命令行中输入nvidia-smi命令查看显卡型号和驱动版本,确认此时的CUDA版本大于等于11.8,否则需要更新nvidia驱动,更新驱动不再赘述。
进入pytorch官网找安装命令
进入pytorch官网的安装页面,搜索索引到2.5.0版本,选择对应的操作系统、包管理器、python版本和CUDA版本,官网会自动生成安装命令,比如对于ubuntu系统,使用conda包管理器,python3.11,CUDA11.8的安装命令如下:
1 | conda install pytorch==2.5.0 torchvision==0.20.0 |
执行安装命令
复制命令到命令行中执行,不过安装过程可能超级超级慢,要么你可以选择耐心等待,或着更聪明的做法是使用国内镜像源进行安装,清华真是太厉害了(doge),下面是切换到清华源的命令:pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple,如果还是慢,可以试试连上手机热点再尝试安装。
验证安装
验证安装是否成功,可以在python环境中输入以下代码,如果输出为True,则说明pytorch安装成功并且可以使用CUDA进行加速了。:
1 | import torch |
下载YOLO源码
拉取源码
去到全球最大同性交友网站GitHub上搜索ultralytics,或直接进入YOLO仓库,找对应版本,可以使用8.3.163版本,直接下载zip包解压到本地,或者使用git命令克隆仓库到本地:
1 | git clone -b 8.3.163 git@github.com:ultralytics/ultralytics.git |
下载官方模型
去到对应网站,找到V8.3.0下面的assets,其中有几百个官方欲训练好的模型,用ctrl+f搜索yolo11n, 下载yolo11n.pt模型文件,下载完成后放到YOLO源码的根目录下,后续训练和推理时会用到这个模型文件。,建议初学时可以下载所有yolo11n-xx.pt模型文件
源码文件夹
找到4.1中下载的yolo源码文件夹,将下载的模型文件移动到该文件夹下,文件准备工作就全部结束了
下载剩余文件
在yolo源码文件夹下,先激活yoloenv环境,然后执行以下命令安装剩余的依赖包:
1 | pip install -e . |
此时所有的环境就已准备就绪了
下载IDE
对于python开发来说,纯命令行的开发可能帅,但是很傻,故绝大多数时候都需要下载一个IDE,一个好的IDE不仅能帮你补全代码,还能图形化的帮你调试代码,管理环境,大大提高开发效率。一般来说常用的两个IDE是Pycharm和宇宙最强IDEVsCode,这两个无需过多介绍,下载和安装直接去官网找对应安装包即可,Pycharm建议进行教育认证后使用专业版,功能更强大,VsCode则是完全免费的,功能也非常强大。两者区别没有特别大,凭个人爱好选择即可。
调用官方模型进行推理
在IDE中(本文教学以Pycharm为例),打开yolo源码文件夹
查看官方图片示例
新建一个Python文件,然后输入以下代码,运行后会在当前目录下生成一个runs文件夹,里面有一个detect文件夹,该文件夹中就存放了官方提供的测试图片的运行结果,里面有一些目标检测的结果,可以看到模型已经成功地对图片中的目标进行了检测,并且标注了类别和置信度。(原图就位于ultralytics/assets/bus.jpg路径下)
1 | from ultralytics import YOLO |
运行结果如下:
摄像头推理
在上面的代码基础上,将source参数改为0,并将save改为False,show改为True。即可使用摄像头进行推理,运行后会弹出一个窗口,显示摄像头的画面,并且对画面中的目标进行检测和标注,按q键可以退出窗口。但是你会注意到,随着时间的推移,窗口会越来越卡,甚至会崩溃,这是因为每次循环都会调用model.predict方法进行推理,而该方法会不断地占用内存,导致内存泄漏,最终导致程序崩溃。为了解决这个问题,我们需要使用stream参数来进行流式推理,这样就不会占用过多的内存了,并且使用opencv控制输出。下面是修改后的代码:
1 | from ultralytics import YOLO |
注意:此时需要安装opencv库,安装命令为
conda install opencv,opencv很大,安装可能持续5,6min,安装完成后再次运行上述代码即可。
训练
coco8数据集对YOLO11n模型进行训练
新建一个train.py文件,输入以下代码,点击运行后就会自动从网上下载coc8数据集,并且使用yolo11n.pt模型进行训练
1 | from ultralytics import YOLO |
需要注意的是,第一次训练很可能失败,原因大概率就是下载数据集失败了,报错信息中有一行如下:Downloading https://ultralytics.com/assets/coco8.zip to xxx,以直接在浏览器中打开前面的链接,手动添加到后续的xxx路径下即可,不需要解压缩。然后在进行训练就可以在runs/train路径下看到训练出来的模型文件了,训练过程中会输出一些日志信息,包括训练的轮数、损失值、精度等指标,可以通过这些信息来判断模型的训练情况。但是初学者一般看不懂这些指标的含义,建议先不关注这些指标,等后续对模型有了一定的了解后再来学习这些指标的含义和作用。训练完成后会在runs/train/weights路径下生成一个best.pt文件,这个文件就是训练好的模型文件,可以用来进行推理了。
上述只提到了一个训练的例子,即最简单的coco8数据集,可以自行尝试其他数据集和其他模型的训练,训练方法基本相同。
数据集查看
安装labelimg标注工具
由于上述安装的python是3.11版本,与本次使用的labelimg标注工具不兼容,所以需要安装一个python3.8版本的环境来使用labelimg,安装方法同4.2.4中创建yoloenv环境的方法,命令如下:
1 | mamba create -n labelimgenv python=3.8 |
创建classes.txt文件
还是以coco8为例,找到数据集图片,数据集标签,然后在数据集标签文件夹里面新建一个名为classes.txt的文件,其中存放了数据集中所有类别的名称,每行一个类别,顺序要和数据集标签文件中的类别编号一致,比如coco8数据集中有80个类别,那么classes.txt文件中就应该有80行,每行对应一个类别的名称,具体的类别名称可以在coco8.yaml文件中找到。复制过来即可,后续在使用labelimg进行标注时会用到这个文件。
使用labelimg查看coco8数据集
记住上述三个内容的路径,打开命令行,输入以下命令:
1 | conda activate labelimgenv |
其中xxx是数据集图片的路径,yyy是classes.txt的路径,zzz是数据集标签的路径。中间用空格隔开,输入完成后按回车键,就会打开labelimg工具,并且自动加载数据集图片和标签了,可以在工具中查看数据集的图片和标签了。
加速训练
训练效率仅能反映训练的快慢,对最终的训练结果没有影响,一个高效的训练一般具有以下特征:
- CUDA利用率有高又稳
- 所有资源利用率都不到100%
要提高训练效率,需要从cpu、显卡、内存等多个方面进行优化,下面是一些常用的优化方法:
调整imgsz大小
一次训练时,需要先将图片在保持原长宽比不变的前提下缩放到指定的大小,然后再统一投喂。默认是640x640,如果显卡显存较小,可以将imgsz适当调小,这样就可以减少每次训练时占用的显存了,从而提高训练效率。注意的是imgsz必须是32的倍数,否则会报错。需要注意的是,此参数不仅会影响训练效率,还会影响训练结果,过大的imgsz严重影响训练效率,过小的imgsz可能会导致模型无法学习到足够的特征,从而导致训练结果不理想,所以需要根据实际情况进行调整。举个最简单的例子,如果你把一张图片压缩到1/10,那么实际图片已经变成一堆马赛克了,训练出来的模型也就只能帮你预测一些马赛克了,遇到正常的图片就完全不行了。放大也是同理。但是一般默认即可,除非原本数据集就过大就过小。
调整batch大小
batch大小指的是每次训练时投喂多少张图片,默认是16。如果样本较大,或者显卡现存较小,无法一次性投喂全部图片,故需要对样本进行分批,适当调小batch大小,这样就可以减少每次训练时占用的显存了,从而提高训练效率。如果一开始不知道要设置为多少,可以先设置为-1,此时在训练前会多一个autobatch环节,可以自动为你找到合适的batch大小。
使用缓存
把cache=False改为cache='ram',这样YOLO就会在训练开始前把所有数据加载到内存中,再全部缩放好,随后等到对应批次时直接投喂给模型就行,唯一缺点就是占用内存较大,如果内存较小,可能会导致系统崩溃,所以需要根据实际情况进行调整。一般在数据集尺寸较大时使用缓存可以大大提高训练效率。
调整workers数量
由于打包是随机的,故没有办法提前打包,打包本身也需要一定时间,如果打包慢了也会影响投喂,解决方法就是多开几个线程来负责打包。
但是同样的,过多的线程也会占用过多的系统资源,一般建议选择一个较小的值。
优化源码
YOLO是基于python编写的,故如果你本身编程语言能力较强,可以尝试优化源码来提高训练效率,但是笔者在此方面是菜鸡,所以不敢妄言,如果有巨佬能提供一些优化建议,欢迎在评论区留言。或者是优化Pytorch和CUDA,那就更牛逼了,如果你还不满足,可以直接修改nvidia驱动或直接硬件魔改显卡,相信你自己。
训练一个自己的模型
数据集准备
在弄明白自己要预测的目标后,你可以先找找网上有没有对应的数据集,如果有的话就直接下载使用,如果没有的话就需要自己收集数据并进行标注了,数据集的准备和标注是一个比较繁琐的过程。
去网上找现成的数据集
可以直接在搜索引擎中搜索你要预测的目标+数据集,或者现在直接使用AI帮你查找,关键词为:预测目标+任务类型+YOLO模型,AI给出来的多数内容无法直接使用,但是它会推荐一些比较出名的数据集就算无法直接使用也可以尝试搜索AI给出的结果,说不定能有意想不到的惊喜。推荐两个网站,我也是在网上看别人推荐的,请自行筛选:roboflow和kaggle,如果找到你需要的数据集,那么恭喜你了,最折磨人的标数据集部分你就可以跳过了。直接看现成数据集使用即可。
现成数据集使用
当你找到正确格式的数据集后,下载其对应的ZIP,建议统一放到源码里的datasets文件夹下,然后把数据集自带的xx.yaml文件复制到ultralytics/cfg文件夹下,然后查看以下内容是否正确:
- path 指向数据集所在地址
- train 指向数据训练集地址
- val 指向数据验证集地址
- test 指向数据测试集地址(可以没有测试集)
- names 指明对应数据集标签的名称,顺序不可更改!!!
- 其他都无所谓了
数据集准备部分你就到此为之了,接下来直接跳到训练部分即可。
自己拍摄数据集
如果你是比较悲惨的那批人,网上没有现成好的开源数据集,例如参加一些大学生竞赛的队员,多数情况都需要你自己来制作自己的数据集,关于材料准备可以尝试以下方法:先随机在不同环境和灯光环境下给目标的各个姿态拍摄几段视频,然后从视频中随机提取n张图片。这里分享一个可以自动完成此过程的脚本:
1 | import cv2 |
使用该脚本前需保证文件路径下有
videos文件夹,其中存放视频格式为.mp4.点击运行则会把全部输出的图片按统一格式存放到images文件夹中,如果数量过多或过少,可以适当调整其中的参数。
眼尖的同学就会发现改脚本完全由AI编写,对于这种简单小功能直接让AI来写还是非常方便和快捷的,后续类似的功能就不再直接给代码了,大家各自拷打自己的AI让它写出能用的代码即可。
数据集标注
数据集准备好了之后就需要进行标注了,标注的工具有很多,比如labelimg、labelme、xlabeling等,初学者可以尝试使用labelimg,安装方法和打开方法上述有提到。具体步骤如下:
- 新建一个
labels文件夹,用于存放标注文件 - 在
labels文件夹中新建一个classes.txt文件用于存放类别名称,根据需要一行一个类别,顺序要和数据集标签文件中的类别编号一致,尽量使用英文名称且尽可能不发生歧义的情况下短小一点。 - 按
使用labelimg查看coco8数据集中教学的方法打开labelimg工具,加载数据集图片和标签。 - 标注前注意标签格式是否为YOLO,如果是的话就可以开始愉快的标数据集了。
A``D可以快速切换图片,W快速创建新的框,框定好后选择对应的标签即可。 - 标完一张图片记得保存,以此类推,直到全部标注完成。标
快速标注方法
例如有100张图片,一张一张的标注可能会比较麻烦,这时就会想到一个办法,先提取其中一部分图片,比如20张,进行标注,然后使用这20张图片训练一个模型,随后使用这个模型对剩余的80张图片进行推理,得到的结果可能不太准确,但可以作为一个初始的标注结果,接下来只需要对这些结果进行修改和完善即可,这样就可以大大减少标注的工作量了。这个方法虽然有点麻烦,但是对于一些比较大的数据集来说是非常有用的,可以大大提高标注效率。至于怎么挑选图片就不必多说了,大家各自拷打自己的AI让它写出能用的代码即可。注意在使用小模型的时候,要把save_txt改为True。
数据集归类
当你准备好了数据集,并且标注好了之后,就需要把数据集按照一定的格式进行归类了,YOLO要求的数据集格式如下:
1 | ├── images/ |
其中images文件夹下存放图片,labels文件夹下存放对应的标签文件,train、val、test分别存放训练集、验证集和测试集的图片和标签,注意图片和标签的文件名要保持一致。此过程还是可以用AI编写脚本完成,请自行鞭策AI。
数据集yaml文件
数据集准备好了之后就需要创建一个yaml文件来描述数据集了,yaml文件的内容主要包括数据集的路径、类别名称等信息,YOLO会根据这个yaml文件来加载数据集进行训练和推理,yaml文件的格式如下:
1 | path: ../dataset |
其中path指向数据集的根目录,train、val、test分别指向训练集、验证集和测试集的图片路径,names是一个字典,键是类别编号,值是对应的类别名称,注意类别名称的顺序要和标签文件中的类别编号一致。创建好yaml文件后,就可以在训练和推理时指定这个yaml文件来加载数据集了。恭喜你,到这里已经创建好了一个自己的数据集了。
模型训练
按照 训练提到的内容进行训练即可,此时使用的就不再是coco数据集了,而是你自己准备的数据集了,需要注意的是,YOLO现在有非常多的模型,但是不同的模型对不同的数据集跑出来的效果可能会有很大的差别,所以在训练时建议尝试所有感兴趣的模型,看看哪个模型在你的数据集上表现最好,当然了,如果你对模型的原理有一定的了解的话,也可以根据数据集的特点来选择合适的模型进行训练,这样可能会更快地得到一个比较好的结果。一般来说,YOLOv8是一个最常被使用的版本,适用于大多数任务,如果你不确定选择哪个版本,可以先从YOLOv8开始尝试,后续如果需要使用其他版本再进行调整即可。
模型推理
训练完成后会在runs/train/weights路径下生成一个best.pt文件,这个文件就是训练好的模型文件,可以用来进行推理了,推理的方法和前面提到的调用官方模型进行推理的方法基本相同,只需要把模型文件路径改为训练好的模型文件路径即可,如果发现效果不理想再调整参数进行重新训练即可。当然,许多时候优化训练参数真不如加大训练集的数量和场景
模型评估
直观评估
训练完成后,可以使用训练好的模型对验证集或测试集进行推理,看看模型的预测结果和真实标签的差距。或者更推荐的是直接用视频进行验证效果更容易看出来,尤其是出现不同场景下的预测效果。
框相近程度IoU
假设实际预测的框为A,真实标签的框为B,$S_{A \cap B}$表示A和B的交集区域,$S_{A \cup B}$表示A和B的并集区域,则IoU可以表示为:
$$
IoU = \frac{S_{A \cap B}}{S_{A \cup B}}
$$
也可以比较直观的发现:IoU的值越大,说明预测的框和真实标签的框越接近,反之则说明预测的框和真实标签的框越远离。一般来说,IoU的值在0到1之间,通常会设置一个阈值,常用阈值为0.5,如果IoU的值大于等于这个阈值,就认为预测的框是正确的,否则就认为预测的框是错误的。
TP、FP、FN
- TP(True Positive)真正例,如IoU算法中提到的,如果预测的框和真实标签的框的IoU值大于等于设定的阈值,那么就认为这个预测是正确的,也就是TP。
- FP(False Positive)假正例,与TP相反,如果预测的框和真实标签的框的IoU值小于设定的阈值,那么就认为这个预测是错误的,也就是FP。
- FN(False Negative)假反例,通俗的来讲就是没找的真实结果。
TP+FP就是预测结果总数
TP+FN就是实际结果总数
精确率、召回率和F1分数
- 精确率(Precision)指的是在所有被预测为正例的样本中,真正例的比例。计算公式为:$$Precision = \frac{TP}{TP + FP}=\frac{正确预测}{预测总数}$$精确率越高,说明预测结果里很多都对了。
- 召回率(Recall)指的是在所有实际为正例的样本中,被正确预测为正例的比例。计算公式为:$$Recall = \frac{TP}{TP + FN}=\frac{正确预测}{真实总数} $$
召回率越高,说明越多的真实结果被找到了。 - F1分数(F1 Score)是精确率和召回率的调和平均数,计算公式为:$$F1 = 2 * \frac{Precision * Recall}{Precision + Recall}$$
F1分数越高,说明模型在精确率和召回率之间取得了更好的平衡。这三个是最常见的评估指标,都是越接近1越好。
预测过程
一次预测的三个步骤
- 预处理:将输入的图片进行缩放、归一化等处理,使其符合模型的输入要求。
- 模型推理:将预处理后的图片输入到训练好的模型中,模型会输出一些预测结果,包括预测的框的位置、类别和置信度等信息。
- 后处理:对模型的输出结果进行后处理,去除掉大部分多余的预测结果,并把图还原成原来的大小。此时后处理是我们此时需要重点关注的。
后处理
- 过滤掉置信度较低的预测结果(conf):模型会输出每个预测结果的置信度,表示模型对这个预测结果的信心程度,通常会设置一个置信度阈值,一般取0.25,只有当预测结果的置信度大于等于这个阈值时,才会保留这个预测结果,否则就会被过滤掉
- 非极大值抑制(NMS):在过滤掉置信度较低的预测结果后,可能会有一些预测结果的位置非常接近,甚至重叠,这时就需要使用非极大值抑制来去除掉这些重复的预测结果。简单来说就是预测相同目标的,只保留置信度最高的一个结果,其他的都丢掉了。注意的是:IoU的值会影响此过程,IoU的值越大,说明预测结果之间的重叠程度越高,那么就越有可能被认为是重复的预测结果,从而被去除掉。
- 限制预测结果(max_det):限制预测结果总数不要超过设定值,一般都很大。
影响
conf越小,预测出来的结果越多,如果把conf设置为0,相当于跳过来去弱,此时精确率P会很小,因为预测出来的结果很多,但是真实的数量又是有限的,但是召回率R有会很大,因为结果很多,所以有可能瞎猫碰到死耗子,一个小概率的框猜对结果。如果把conf稍微调高一点,那就会把一部分低概率的排除掉,低概率的结果大概率都是错误的,所以精确率P会提高,但是召回率R会降低,因为上述提到的瞎猫碰到死耗子的正确的结果被排除掉了。总之,conf的值需要根据实际情况进行调整,找到一个合适的平衡点,既能保证预测结果的数量,又能保证预测结果的质量。
PR曲线,mAP50,mAP50-95
- PR曲线:PR曲线是精确率和召回率之间的关系的曲线图,通过PR曲线可以直观地看到模型在不同的置信度阈值下的表现,PR曲线越接近右上角,说明模型的表现越好。PR曲线和坐标轴包围的面积就是AP值,AP值越大,说明模型在单一类别的表现越好。mAP就是所有类别的AP值的平均值,mAP越大,说明模型在所有类别上的表现越好。
潜台词为:能找到一个对应的conf值,使P和R都尽可能的高,那么这个模型就比较好了。
- mAP50:mAP50是指在IoU阈值为0.5时的平均精确率,mAP50越高,说明模型在IoU阈值为0.5时的表现越好。
- mAP50-95(平均平均平均精度):mAP50-95是指在IoU阈值从0.5到0.95之间的平均精确率,mAP50-95越高,说明模型在IoU阈值从0.5到0.95之间的表现越好。
总结
通过上述描述我们就知道了描述模型好坏的4个重要指标:精确率P、召回率R、mAP50和mAP50-95,通常来说,模型的表现越好,这四个指标的值就越高,但是在实际应用中,这四个指标之间可能会存在一定的权衡关系,需要合理取舍。
未完待续
由于笔者也是刚开始接触深度学习与计算机视觉,所以在写这篇文章的时候也是边学边写的,后续等积攒一定调试训练经验之后会继续更新这篇文章或者写一篇新的文章来分享一些训练和调试模型的经验和技巧,敬请期待。
- 标题: 如何从零开始学习使用yolo
- 作者: HeWenXuan
- 创建于 : 2026-02-16 16:02:28
- 更新于 : 2026-02-18 17:04:13
- 链接: https://redefine.ohevan.com/2026/02/16/yolo-learn/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。